در این قسمت تیم کدگیت را با آموزش خوشه بندی k میانگین در پایتون (K means) همراهی کنید. در ابتدای آموزش الگوریتم K means را معرفی کرده سپس به پیاده سازی این الگوریتم در زبان برنامه نویسی پایتون میپردازیم. پیشنهاد میکنیم پیش از مطالعه این جلسه، پیشنیازهای زیر را بررسی کنید:
k میانگین
روش خوشه بندی k-means یک روش یادگیری ماشین بدون نظارت (unsupervised) است که برای شناسایی خوشهها در یک مجموعه داده استفاده می شود. به طور کلی انواع مختلفی از روشهای خوشه بندی وجود دارد ، اما k-means یکی از قدیمی ترین الگوریتمها است.
این الگوریتم دیتا را به k گروه مشابه طبقه بندی می کند. برای محاسبه این شباهت، از فاصله اقلیدسی به عنوان اندازه گیری استفاده می شود. دیتایی که بر روی آن خوشهبندی انجام خواهیم داد Iris dataset میباشد(دانلود دیتاست).
خوشه بندی k میانگین در پایتون
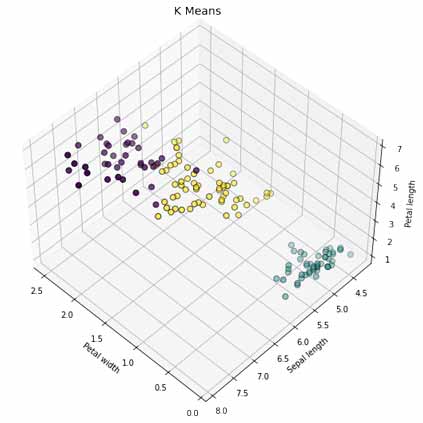
همانطور که میدانید دیتاست IRIS از قبل در 3 گروه Iris-setosa و Iris-versicolor و Iris-virginica دستهبندی شده است. در زیر تصویری از دستهبندی واقعی این دیتاست را میبینیم(نمودار زیر بر اساس 3 متغیر PetalWidthCm و SepalLengthCm و PetalLengthCm میباشد). پس از پیاده سازی نیز دسته بندی را با کمک الگوریتم K means خواهیم دید.
برای پیاده سازی k میانگین ابتدا کتابخانههای مورد نیاز را فراخوانی میکنیم:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
در ادامه دیتاست خود را وارد برنامه میکنیم.
df = pd.read_csv("Iris.csv",index_col=0)
الگوریت k means بدون نظارت بوده پس تنها متغیر X را برای آن مشخص میکنیم:
feature_columns = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm','PetalWidthCm']
X = df[feature_columns]
حال به پیاده سازی خوشه بندی k میانگین در پایتون به کمک کتابخانه sklearn میپردازیم:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, max_iter = 300, random_state = 0)
kmeans.fit(X)
برای نمایش نقاط وسط خوشه ها از تابع cluster_centers_ استفاده میکنیم:
centers = kmeans.cluster_centers_
print(centers)
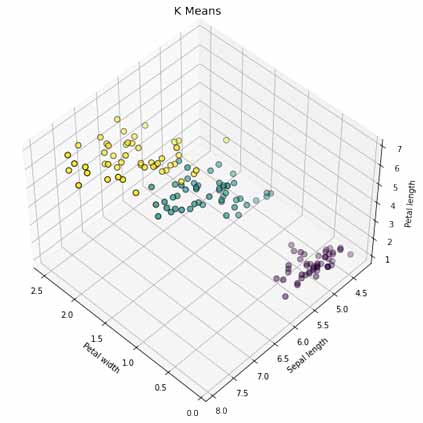
پیشبینی خوشه های ما به صورت زیر است. میتوانید با نمودار بالا آن را مقایسه کنید.
روش elbow
یکی از مشکلات روش k میانگین، انتخاب درست عدد k است. در صورتی که تعداد k درست تعیین نگردد الگوریتم ما به درستی کار نمیکند. یکی از روشهایی که این مشکل را برطرف کرده است روش Elbow است.
انتخاب k
برای انتخاب بهترین k معمولا الگوریتم را با تعداد خوشههای مختلف سنجیده و میزان خطا را محاسبه میکنند. نمودار زیر را ببینید:

در نمودار بالا همانطور که میبینید وقتی تعداد خوشه ها از 1 به 2 می رسد خطا میزان زیادی کاهش پیدا می کند همین طور از 2 به 3 همین اتفاق میافتد. اما از تعداد خوشه 3 به 4 میزان خطا نسبت به مراحل قبل کاهش چشمگیری نداشته است. می توان این نتیجه را گرفت که تعداد خوشه 3 میزان مناسبی برای انتخاب k است. البته به این نکته توجه داشته باشید که هر چه تعداد k بالاتر برود میزان خطا پایین تر میآید و این امری بدیهی است. شکل نمودار بالا شبیه به آرنج میباشد و elbow نیز به معنی آرنج است.