در این قسمت تیم کدگیت را با آموزش k نزدیکترین همسایه در پایتون (KNN) همراهی کنید. در ابتدای این جلسه الگوریتم KNN را توضیح و سپس به پیاده سازی آن در پایتون به کمک کتابخانه Sklearn میپردازیم. پیشنهاد میکنیم قبل از مطالعه این جلسه آموزش رگرسیون خطی در پایتون را مطالعه نمایید.
K نزدیکترین همسایه
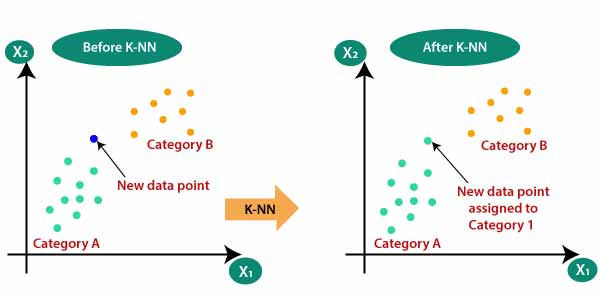
طبقهبندی مبتنی بر k نزدیکترین همسایه (knn) یکی از روشهای طبقهبندی معروف غیرپارامتری هست و با یک رویکرد بسیار ساده و کارا از همسایه برای دسته بندی داده جدید استفاده میکنند. در این روش تنها دادهها را ذخیره کرده و از آنها برای دسته بندی همسایه ها استفاده می کنند. به خاطر پیادهسازی ساده و همچنین عملکرد بالای این الگوریتم در اکثر پروژهها و مقالات استفاده میشود.
K نزدیکترین همسایه در پایتون
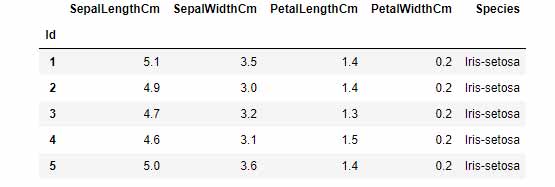
برای پیاده سازی الگوریتم knn ما از کتابخانه sklearn استفاده میکنیم. دیتایی که بر روی آن دستهبندی انجام خواهیم داد Iris dataset میباشد(دانلود دیتاست iris). تصویر زیر سطرها و ستونهای این دیتاست را نشان میدهد.
پیش پردازش دیتا
قبل از پیاده سازی الگوریتم knn دیتای خود را بررسی میکنیم و در صورت نیاز تغییراتی را بر روی آن اعمال میکنیم.
در گام نخست دیتای خود را وارد برنامه میکنیم.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("Iris.csv",index_col=0)
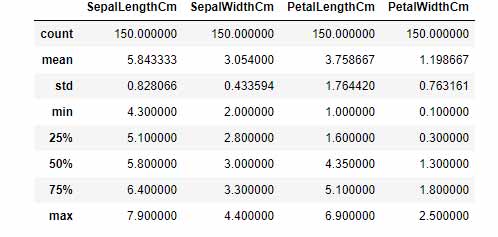
سپس به کمک توابع info و describe اطلاعات کلی راجع به دیتاست بدست میآوریم.
df.describe()
df.info()
خروجی تابع Describe به صورت زیر میباشد:
خروجی تابع info به صورت زیر میباشد:
class 'pandas.core.frame.DataFrame'>
Int64Index: 150 entries, 1 to 150
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 SepalLengthCm 150 non-null float64
1 SepalWidthCm 150 non-null float64
2 PetalLengthCm 150 non-null float64
3 PetalWidthCm 150 non-null float64
4 Species 150 non-null object
dtypes: float64(4), object(1)
متغیرهای x و y را تعیین میکنیم:
feature_columns = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm','PetalWidthCm']
X = df[feature_columns]
y = df['Species']
متغیر y از سه گروه [‘Iris-setosa’, ‘Iris-versicolor’, ‘Iris-virginica’] تشکیل شده است. برای سادگی اسامی این سه گروه را به اعداد 1 و 2 و 3 تقسیم میکنیم. کد این عملیات به صورت زیر میباشد:
y = df['Species'].replace(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'],[1,2,3])
پیاده سازی K نزدیکترین همسایه در پایتون
حال بعد از پردازش دیتا ما به پیاده سازی الگوریتم knn میپردازیم. برای این کار دیتا را به دو قسمت test و train تقسیم میکنیم.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.30)
الگوریتم knn را بر روی دیتاست اعمال میکنیم (دقت کنید k = 2 قرار دادیم):
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train,y_train)
pred = knn.predict(X_test)
نوبت به ارزیابی الگوریتم رسیده است. به کمک کتابخانه sklearn مدلسازی که انجام دادیم را ارزیابی میکنیم:
from sklearn.metrics import classification_report
print(classification_report(y_test,pred))
خروجی ارزیابی به صورت زیر است:
precision recall f1-score support
1 1.00 1.00 1.00 16
2 0.93 1.00 0.96 13
3 1.00 0.94 0.97 16
accuracy 0.98 45
macro avg 0.98 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
98 درصد صحیح (نتیجه خوبیه!). شما با تغییر k میتوانید نتیجه الگوریتم رو تغییر بدید.
اگر سوالی در خصوص k نزدیکترین همسایه در پایتون دارید در قسمت کامنت سوال خود را مطرح کنید تا پاسخگوی شما باشیم.