

در این قسمت تیم کدگیت را با آموزش رگرسیون خطی در پایتون همراهی کنید. در این جلسه ابتدا رگرسیون خطی را معرفی میکنیم. در ادامه با کمک کتابخانههای پایتون به پیاده سازی و تحلیل دیتا خواهیم پرداخت.
رگرسیون خطی در پایتون
فرض کنید اطلاعات نمودار زیر در اختیار ما قرار داده شده است. برای توصیف دیتاهای زیر و پیدا کردن مدل خطی بین دو متغیر از رگرسیون خطی استفاده میشود. پس میتوان گفت رگرسیون خطی تلاش میکند یک رابطه بین متغیر وابسته (Y) و مستقل (X) را مدل سازی کند.
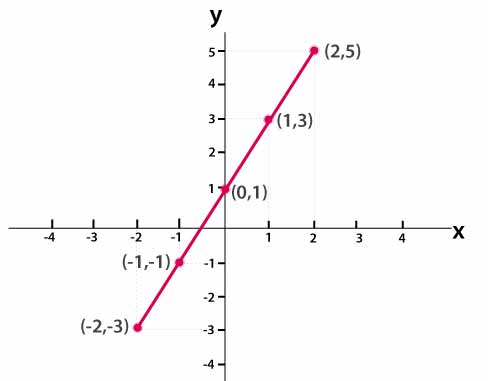
نحوه محاسبات در رگرسیون خطی را به شما دوستان می سپاریم و در این آموزش به کاربرد و پیاده سازی آن پرداخته خواهد شد.
پیاده سازی رگرسیون خطی در پایتون
برای پیاده سازی رگرسیون خطی ما از کتابخانههای Pandas، Matplotlib، Numpy و sklearn استفاده میکنیم. ابتدا کتابخانهها را import میکنیم:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
در این مرحله باید دیتایی که بر روی آن میخواهیم پردازش شود را انتخاب کنیم. دیتا که ما از آن استفاده خواهیم کرد به صورت زیر میباشد. در این دیتا بر اساس تجربه افراد میزان حقوق آنها محاسبه شده است.(دانلود دیتاست)
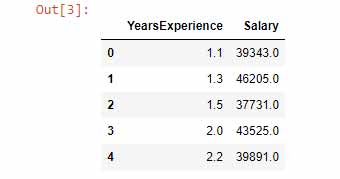
برای پیاده سازی رگرسیون خطی ابتدا دیتا را میخوانیم.
Salary = pd.read_csv('Salary_Data.csv')
اطلاعات کلی با کمک تابع Describe از دیتابیس خود بدست میآوریم:
Salary.info()
خروجی کد بالا به صورت زیر میباشد:
class 'pandas.core.frame.DataFrame'>
RangeIndex: 30 entries, 0 to 29
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 YearsExperience 30 non-null float64
1 Salary 30 non-null float64
dtypes: float64(2)
memory usage: 544.0 bytes
با کمک کتابخانه seaborn نمودارهای Distplot و heatmap دیتاها را میکشیم (دستور این توابع در قسمت دانلود سورس کد آورده شده):
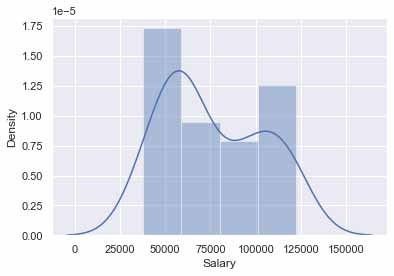
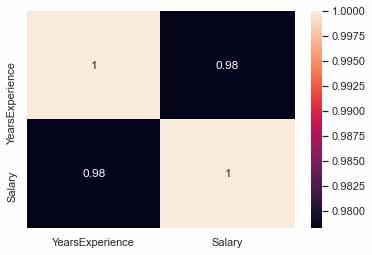
توزیع میزان حقوق مناسب بوده و نیاز به پیش پردازش خاصی ندارد. حال نوبت به پیاده سازی رگرسیون خطی برای دیتا ما است. متغیر وابسته و مستقل را تعیین میکنیم:
X = Salary['YearsExperience']
y = Salary['Salary']
حال به کمک کتابخانه sklearn به پیاده سازی رگرسیون میپردازیم.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4)
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
lm.fit(X_train,y_train)
predictions = lm.predict(X_test)
برای دانستن ضرایب فرمول بدست آمده به کمک رگرسیون خطی کد زیر را میزنیم:
lm.coef_
#array([9540.1453911])
print(lm.intercept_)
# 25658.229427159044
فرمول بدست آمده توسط رگرسیون خطی به صورت زیر است:
Y=25658.229427159044 + 9540.1453911 * X
حال برای بدست آوردن Mean square Error و R Square از کد زیر استفاده میکنیم:
from sklearn.metrics import r2_score,mean_squared_error
mean_squared_error(y_test,predictions)
# 30857021.39780877
r2_score(y_test,predictions)
# 0.9574365522884438
خروجی نتیجه رگرسیون ما خوبه. شما دوستان میتونید روی این دیتا کار کنید و میزان MSE را کمتر و R Square رو به 1 نزدیکتر کنید.
اگر سوالی در خصوص رگرسیون خطی دارید در قسمت کامنت سوال خود را مطرح کنید تا پاسخگوی شما باشیم.











سلام وقت بخیر.کد آماده NSGA2 در پایتون رو ندارین؟
سلام. خیر این کد را نداریم.
اموزش بسیار مفید، کوتاه و دقیقی بود. ممنونم
سلام اموزش خیلی خوبی بود.
اگر بخواهیم precision وrecall رو هم برای این دو ستون در رگرسیون بدست بیاریم باید چکار کنیم. ممنون
سلام چجوری میشه میزان rscoreو زیاد و mseو کاهش داد ؟
سلام. برای بهتر شدن نتیجه در رگرسیون:
تنظیمات و پارامترهای مسئله رو بررسی کنید.
دیتا را نرمال کنید.
دیتا وابسته و غیر وابسته را شناسایی و ابعاد را کاهش دهید.