
در این جلسه تیم کدگیت را با آموزش دسته بند بیز ساده در پایتون همراهی کنید. ابتدای این جلسه دستهبند بیز ساده را توضیح داده و سپس به پیاده سازی این الگوریتم (به کمک دیتاست Social network ads و کتابخانه sklearn) در پایتون میپردازیم. پیشنهاد میکنیم پیش از مطالعه این جلسه، آموزشهای زیر را مرور کنید:
بیز ساده
دستهبند بیز ساده یک الگوریتم دستهبندی (Classification) بر اساس تئوری بیز میباشد. به زبان ساده ، این الگوریتم فرض می کند که وجود یک ویژگی خاص در یک کلاس با ویژگی دیگر ارتباطی ندارد.
به عنوان مثال، میوه ای اگر قرمز، گرد و قطر حدود 8 سانتیمتر باشد، ممکن است یک سیب در نظر گرفته شود. حتی اگر این ویژگی ها به یکدیگر یا وجود ویژگی های دیگر بستگی داشته باشند، همه این خصوصیات به طور مستقل در احتمال سیب بودن این میوه نقش دارند و به همین دلیل به “naive” معروف است (naive به معنی ساده لوح میباشد).
ساخت مدل Naive Bayes به ویژه برای دادههای بسیار بزرگ آسان است. همراه با سادگی، Naive Bayes از بسیاری الگوریتمها عملکرد بهتری دارد.
دسته بند بیز ساده در پایتون
برای پیاده سازی بیز ساده ابتدا دیتاست خود را وارد برنامه میکنیم.
دیتاست
برای پیاده سازی بیز ساده ما از دیتاست زیر استفاده میکنیم(دانلود دیتاست). در این دیتاست افرادی که با استفاده از تبلیغات آنلاین اقدام به خرید کردهاند، دستهبندی شدهاند.
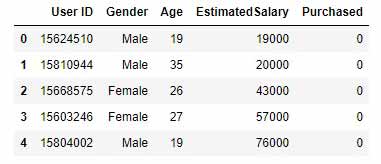
این دیتاست شامل پنج ستون میشود:
- ستون اول یک کد برای کاربران است.
- ستون دوم جنسیت کاربر است.
- ستون سوم سن کاربر است.
- ستون چهارم میزان حقوق دریافتی میباشد. مقدار این ستون تقریبی است و دقیق نمیباشد.
- مقادیر ستون پنجم صفر (0) و یک (1) میباشد. در صورت خرید کاربر مقدار این ستون 1 میشود. در غیر این صورت مقدار این ستون صفر است.
به کمک دیتاست فوق و الگوریتم naïve Bayes ما میخواهیم پیشبینی کنیم که کاربران ما با توجه به سن و حقوق دریافتی اقدام به خرید آنلاین خواهند کرد یا خیر.
پیشپردازش
در گام اول دیتاست خود را وارد برنامه میکنیم همچنین کتابخانههای مورد نیاز خود را فراخوانی میکنیم:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme()
df = pd.read_csv('Social_Network_Ads.csv')
حال نوبت به بررسی دیتاست به کمک توابع info و describe رسیده است:
df.describe()
df.info()
خروجی توابع بالا به صورت زیر است (خروجی ها به ترتیب است):
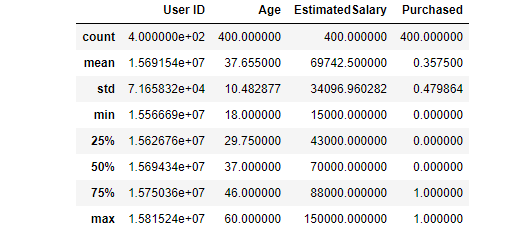
class 'pandas.core.frame.DataFrame'>
RangeIndex: 400 entries, 0 to 399
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 User ID 400 non-null int64
1 Gender 400 non-null object
2 Age 400 non-null int64
3 EstimatedSalary 400 non-null int64
4 Purchased 400 non-null int64
dtypes: int64(4), object(1)
بر اساس توابع بالا دیتاست ما شامل 400 سطر بوده و مقدار Null در دیتا نمیباشد. مقادیر X و Y دیتا را مشخص میکنیم:
x=df[["Age","EstimatedSalary"]]
y=df['Purchased']
پیاده سازی بیز ساده در پایتون
دیتا را به دو قسمت test و train تقسیم میکنیم.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x,y,test_size=0.25,random_state=0)
حال دستهبند بیز ساده در پایتون را به کمک کتابخانه sklearn پیاده سازی میکنیم:
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(X_train, y_train)
برای ارزیابی خطا الگوریتم خود کد زیر را میزنیم:
print(classifier.score(X_test,y_test))
خروجی کد بالا برابر با 0.9 است نتیجه مناسبی است. برای تغییر در نتیجه شما میتوانید دیتاها را نرمال کنید و یا الگوریتمهای مانند svm را با naïve Bayes مقایسه کنید.
اگر سوالی در خصوص دسته بند بیز ساده در پایتون دارید در قسمت کامنت سوال خود را مطرح کنید تا پاسخگوی شما باشیم.











خود الگوریتم naïve Bayes را چطوری باید پیاده سازی کرد؟
سلام. برای پیاده سازی naive bayes باید درک خوبی از الگوریتم و فرمول آن داشته باشید.