


")
در این قسمت تیم کدگیت سورس طبقه بندی داده های Iris با الگوریتم SVM را تهیه کرده است. یادگیری ماشین وارد دنیای روزمره ما انسانها شده است. دیگر از طریق یک تلفن همراه و نصب اپلیکیشن میتوان یک بیماری را تشخیص داد. یادگیری ماشین، هوش مصنوعی و تمامی شاخههای آن در دنیای امروز کاربردهای بسیاری پیدا کرده است. با توجه به گسترش این شاخه از علم، ما نیز تصمیم گرفتیم سورسی از همین رشته تهیه و آماده سازی نماییم. سورس طبقه بندی گلهای زنبق که از الگوریتم SVM استفاده میکند. با ما همراه باشید تا این سورس جذاب را معرفی کنیم.
سورس طبقه بندی داده های Iris با الگوریتم SVM
تکنولوژی امروزه به سرعت در حال پیشرفت است. تشخیص عینک، تشخیص خودرو، تشخیص چشم و … تنها بخشی از پیشرفت تکنولوژی است که با کمک پردازش تصویر، بینایی ماشین و هوش مصنوعی قابل انجام است. در این قسمت سورس سورس طبقه بندی داده های Iris با الگوریتم SVM در پایتون را تهیه کردهایم. برای این کار ما از ماژول sklearn و seaborn و numpy و pandas و matplotlib کمک میگیریم. در صورتی که با این ماژولها آشنایی ندارید پیشنهاد میکنیم دوره آموزش پیش نیاز علم داده را مطالعه نمایید چراکه در این دوره تمامی ماژولهای فوق (به استثنا sklearn) آموزش داده میشوند. همچنین دیتاست استفاده گردیده در این پروژه IRIS Dataset میباشد.
دیتاست IRIS
همانطور که میدانید دیتاست IRIS (یا مجموعه داده گل زنبق) در 3 گروه Iris-setosa و Iris-versicolor و Iris-virginica دستهبندی شده است. پارامترهای این دیتاست به صورت زیر می باشد:
- طول کاسبرگ (sepal length)
- عرض کاسبرگ (sepal width)
- طول گلبرگ (petal length)
- طول گلبرگ (petal length)
در زیر تصویری از دستهبندی واقعی این دیتاست را میبینیم(نمودار زیر بر اساس 3 متغیر PetalWidthCm و SepalLengthCm و PetalLengthCm میباشد).
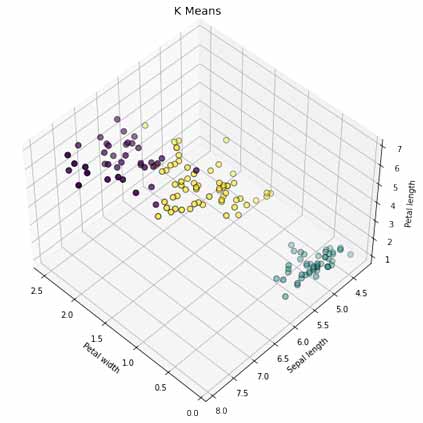
با کمک این دیتاست الگوریتم های یادگیری ماشین را پیاده سازی کرده و آن را تست میکنند. ما نیز از این دیتاست استفاده خواهیم کرد.
نحوه اجرا سورس طبقه بندی داده های Iris
زبان برنامه نویسی سورس طبقه بندی داده های Iris، پایتون بوده و فرمت فایل .py است. بعد از تهیه سورس از سایت کدگیت فایلی با فرمت zip در اختیار شما قرار میگیرد. فایل را از حالت zip خارج کرده تا بتوانید سورس کد را ببینید. فایل اصلی برنامه با نام SVM Iris Dataset.py میباشد. این فایل را اجرا کنید تا برنامه اجرا شود. پس از اجرا خروجی زیر را مشاهده خواهید کرد:
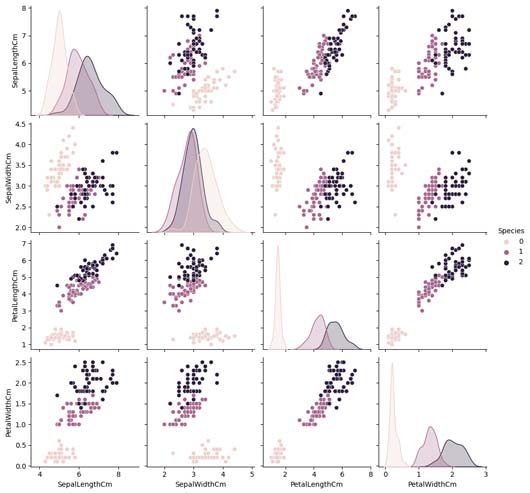
مقایسه متغیرهای دیتاست در یک نمودار
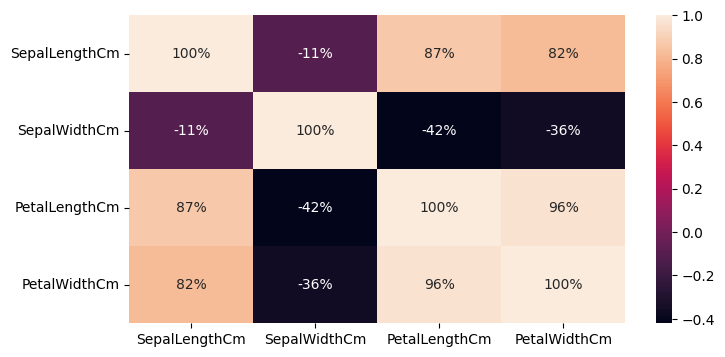
بررسی وابستگی ویژگیها
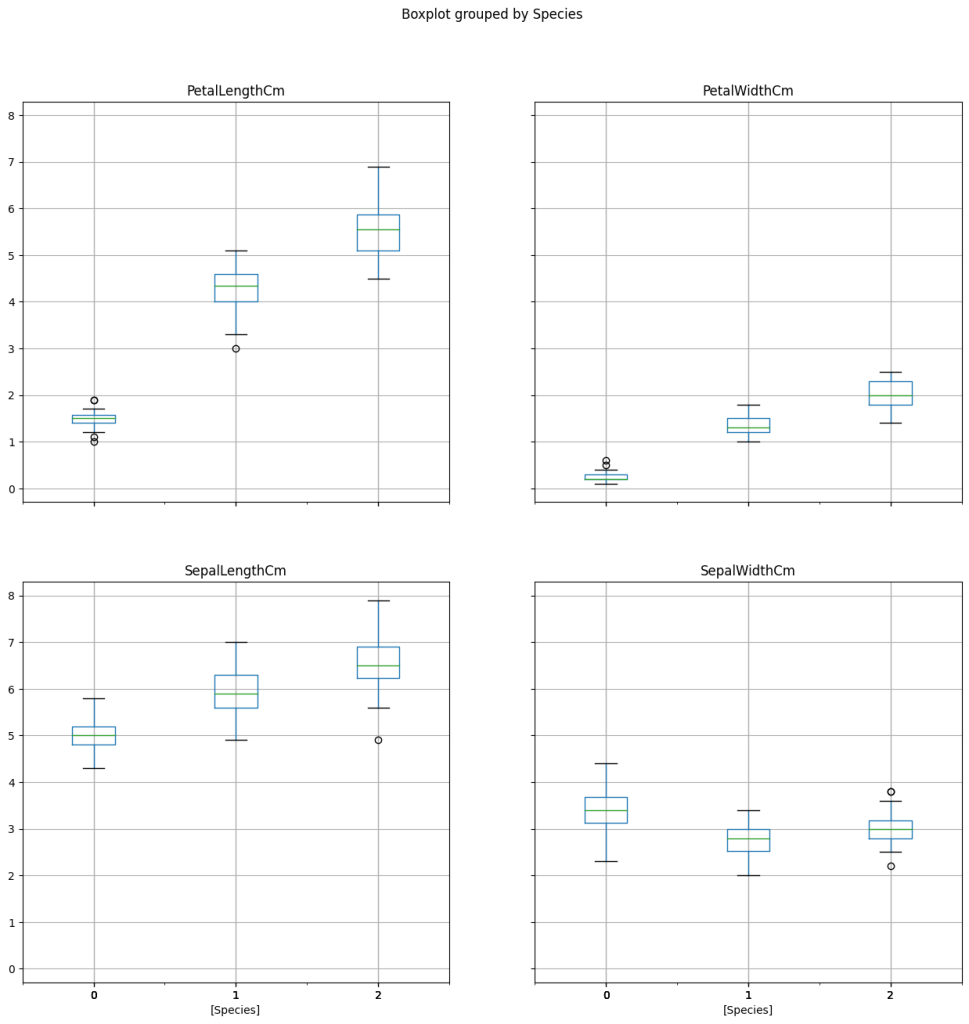
مقایسه ویژگی ها با Boxplot
علاوه بر تصاویر بالا در کنسول، خروجی زیر را خواهید دید:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
0 1 5.1 3.5 1.4 0.2 Iris-setosa
1 2 4.9 3.0 1.4 0.2 Iris-setosa
2 3 4.7 3.2 1.3 0.2 Iris-setosa
3 4 4.6 3.1 1.5 0.2 Iris-setosa
4 5 5.0 3.6 1.4 0.2 Iris-setosa
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm
count 150.000000 150.000000 150.000000 150.000000 150.000000
mean 75.500000 5.843333 3.054000 3.758667 1.198667
std 43.445368 0.828066 0.433594 1.764420 0.763161
min 1.000000 4.300000 2.000000 1.000000 0.100000
25% 38.250000 5.100000 2.800000 1.600000 0.300000
50% 75.500000 5.800000 3.000000 4.350000 1.300000
75% 112.750000 6.400000 3.300000 5.100000 1.800000
max 150.000000 7.900000 4.400000 6.900000 2.500000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Id 150 non-null int64
1 SepalLengthCm 150 non-null float64
2 SepalWidthCm 150 non-null float64
3 PetalLengthCm 150 non-null float64
4 PetalWidthCm 150 non-null float64
5 Species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
None
Shape: (150, 6)
SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
Species
0 50
1 50
2 50
Name: count, dtype: int64
Train Shape (112, 4)
Test Shape (38, 4)
The accuracy of the SVC is 0.9736842105263158
در خروجی بالا اطلاعات زیر قرار گرفته است:
- ابعاد دیتاست
- اطلاعات آماری دیتاست
- دیتاست بعد از اعمال پیش پردازش
- ابعاد دیتاست train و test
- دقت مدل پس از train
- …
فایلها و ماژولها سورس کد
در سورس طبقه بندی داده های Iris از فایلها و ماژولهای زیر استفاده گردیده است:
- Numpy: نصب numpy با دستور pip install numpy از طریق cmd انجام میشود.
- pandas: با دستور pip install pandas از طریق cmd، نصب این ماژول انجام میشود.
- matplotlib: دستور pip install matplotlib را در cmd بزنید.
- seaborn: برای نصب seaborn نیز در cmd دستور pip install seaborn را بنویسید.
- scikit-learn: نصب scikit-learn با دستور pip install scikit-learn از طریق cmd انجام میشود.
برای نصب پایتون به طوری که در CMD بتوانید کدهای پایتون را اجرا و ماژولها را نصب نمایید ویدئو زیر را حتماً مشاهده کنید:













نقد و بررسیها
هنوز بررسیای ثبت نشده است.