در این جلسه ما را با آموزش پیاده سازی شبکه عصبی در پایتون همراهی کنید. این آموزش شامل فراخوانی دیتاست در پایتون، پیشپردازش اطلاعات، پیاده سازی شبکه عصبی با دو Hidden Layer و تست شبکه می باشد. دقت کنید در این آموزش از کتابخانه Tensorflow استفاده خواهیم کرد. پیشنیاز این آموزش شامل موارد زیر است:
فراخوانی دیتا
دیتایی که در این جلسه از آن استفاده خواهیم کرد مربوط به مشتریان بانک هستند. این فایل در کنار سورس کد این جلسه قرار داده شده است. ما می خواهیم بدانیم که مشتریان، بانک را ترک خواهند کرد یا خیر. ستونهایی که در این دیتاست خواهید دید شامل موارد زیر هستند:
- Row number: شماره سطر
- Customerid: یک id منحصر به فرد برای هر یک از مشتریان
- Surname: نام خانوادگی
- CreditScore: امتیاز مشتری
- Geography: کشور مشتری
- Gender: جنسیت
- Age: سن
- Tenure: مدت زمانی که مشتری بانک بودهاند
- Balance: موجودی حساب
- NumOfProducts: تعداد سرویس یا خدماتی که از بانک دریافت کرده است.
- HasCrCard: مشتری دارای کارت اعتباری است یا خیر
- IsActiveMember: مشتری فعال بانک می باشد یا خیر
- EstimatedSalary: حقوق پیشبینی شده مشتری
- Exit: بانک را ترک کرده یا خیر.
نوبت به کد رسیده و فراخوانی این دیتاست. برای این کار ما از کتابخانه Pandas استفاده میکنیم. فرمت فایل csv بوده پس از تابع read_csv استفاده میکنیم. کد زیر برای فراخوانی دیتاست استفاده میشود:
import numpy as np
import pandas as pd
import tensorflow as tf
# Importing the dataset
dataset = pd.read_csv('Churn_Modelling.csv')
X = dataset.iloc[:, 3:-1].values
y = dataset.iloc[:, -1].values
در کد بالا ما X و Y را مشخص کردیم تنها نکته موجود در این قسمت در نظر گرفتن مقادیر x از ستون سوم به بعد است. به نظر شما دلیل این کار چه بود؟ لطفا پاسخ خود را در قسمت کامنت بنویسید.

پیشپردازش دیتا
پیش پردازش دیتا بسیار مهم و حیاتی است چراکه هرنوع دیتایی که در دنیای واقعی وجود دارد نیازمند بررسی و تصحیح اطلاعات است. در این قسمت دیتایی که در مرحله فراخوانی کردیم را پیش پردازش میکنیم. اگر نگاهی به دیتاست بکنید متوجه خواهید شد که ستون های کشور مشتری و جنسیت به صورت رشته و بقیه ستونها با عدد نوشته شدهاند. ما نیاز داریم که دو ستون کشور مشتری و جنسیت را تغییر دهیم تا مطابق با بقیه دیتاست شود. دقت کنید ما در مرحله قبل ستونهای ردیف، id مشتری و نام خانوادگی مشتری را در دیتاست حذف کردیم پس نیازی به تحلیل این سه ستون نیست. کد این مرحله به صورت زیر است:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
X[:, 2] = le.fit_transform(X[:, 2])
print(X)
# One Hot Encoding the "Geography" column
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])], remainder='passthrough')
X = np.array(ct.fit_transform(X))
print(X)
ما برای ستون جنسیت از LabelEncoder و برای ستون کشور مشتری از OneHotEncoder استفاده کردیم. خروجی ستون های بعد از پیشپردازش به صورت زیر است:
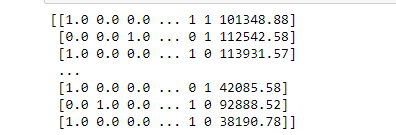
نرمال سازی
بعد از اینکه دیتاست ما پیش پردازش لازم بر روی آن انجام شد نیاز است که دیتاست به دو قسمت train و test تقسیم شود. همچنین برای اینکه نتیجه مطلوبتری از شبکه عصبی دریافت کنیم از feature scaling نیز استفاده میکنیم. این دو عملیات نیز قسمتی از پیش پردازش است اما بدلیل اهمیت آنها در عنوانی جداگانه در این آموزش ارائه شد.
برای تقسیم دیتاست از کد زیر استفاده می کنیم:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
پیاده سازی Feature Scaling نیز به صورت زیر میباشد:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
پیاده سازی شبکه عصبی در پایتون
بعد از پیش پردازش نوبت به پیادهسازی شبکه عصبی و Train آن می رسد. با کمک کتابخانه Tensorflow یک شبکه عصبی ایجاد خواهیم کرد. سپس آن را Train می کنیم. شبکه عصبی که پیاده سازی میکنیم شامل یک لایه ورودی و دو لایه مخفی (Hidden layer) می باشد. کد این قسمت به صورت زیر میباشد:
# Initializing the ANN
ann = tf.keras.models.Sequential()
# Adding the input layer and the first hidden layer
ann.add(tf.keras.layers.Dense(units=6, activation='relu'))
# Adding the second hidden layer
ann.add(tf.keras.layers.Dense(units=6, activation='relu'))
# Adding the output layer
ann.add(tf.keras.layers.Dense(units=1, activation='sigmoid'))
# Part 3 - Training the ANN
# Compiling the ANN
ann.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
# Training the ANN on the Training set
ann.fit(X_train, y_train, batch_size = 32, epochs = 100)
تست شبکه عصبی
بعد از اینکه شبکه عصبی خود را Train کردیم نیاز است که آن را بسنجیم. برای تست می توان از confusion matrix استفاده کرد. در قسمت نرمال سازی دیتاست خود را به دو قسمت test و train تقسیم کردیم. دیتا test در این مرحله برای سنجش شبکه استفاده خواهیم کرد. کد این مرحله به صورت زیر است:
y_pred = ann.predict(X_test)
y_pred = (y_pred > 0.5)
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print(cm)
accuracy_score(y_test, y_pred)
خروجی کد بالا به صورت زیر است:
[[1510 85]
[ 194 211]]