در این جلسه تیم کدگیت را با آموزش پرسپترون در پایتون همراهی کنید. پرسپترون یکی از ابتداییترین شبکههای عصبی است که امروزه میتوان آن را در کامپیوترهای شخصی پیاده سازی کرد. دراین جلسه یک پرسپترون را پیاده سازی کرده و با استفاده از دیتاست Iris، پرسپترون را تست خواهیم کرد. پیشنهاد میکنیم برای درک بهتر این جلسه، آموزشهای زیر را مطالعه نمایید:
- حلقه For در پایتون
- توابع در پایتون
پرسپترون چیست؟
پرسپترون یکی از سادهترین معماریهای ANN است که در سال 1958 توسط فرانک روزنبلات معرفی شد. پرسپترون مدلی از شبکه عصبی تک لایه است که برای مسائل طبقهبندی دو کلاسه استفاده میشود. تصویر زیر یک نمونه پرسپترون میباشد:
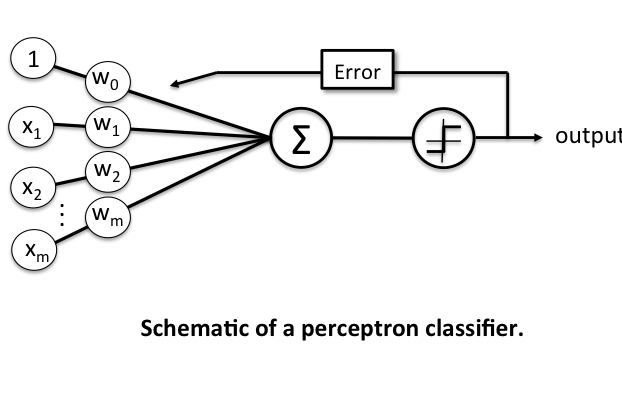
همانطور که در تصویر بالا میبینید پرسپترون ورودی Xi می گیرد. سپس هر ورودی با وزنهای W ضرب میشود و در تابع سیگما مجموع آنها محاسبه میگردد. در پایان با توجه به Threshold Function خروجی محاسبه میگردد. حال برای Train کردن یک پرسپترون نیاز است که میزان خطا را بدست آورده و وزنها را با توجه به خطا بدست آمده تغییر دهیم.
فرمول پرسپترون
برای پیاده سازی پرسپترون در پایتون نیاز است که با فرمولهای آن آشنا باشید. قدم اول ورودی مسئله است. ورودی ها شامل X و Y هستند. خروجی Y به صورت باینری است و برای پیاده سازی ما -1 یا 1 می باشد. X می تواند هر عددی باشد. W را وزن های پرسپترون تعریف میکنیم. برای مقداردهی اولیه، W را مقدار بین صفر تا یک در نظر میگیریم. فرمول بروزرسانی وزنها به صورت زیر است:
w = w + learning_rate * (expected – predicted) * x
Learning Rate مقداری است که توسط ما انتخاب میشود و معمولا عدد کوچکی است. Expected همان Y است و predicted مقدار پیشبینی شده توسط پرسپترون میباشد. X نیز در بالا تعریف شد.
Train کردن پرسپترون
برای Train کردن ابتدا وزنهای رندوم به پرسپترون میدهیم. X و Y را تعیین میکنیم. برای تعیین X و Y ما از دیتاست Iris که در زیر آورده شده استفاده میکنیم:
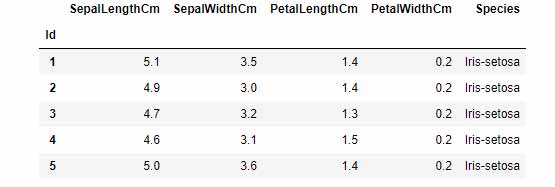
در پیاده سازی ما ستونهای SepalLengthCm و PetalLengthCm مقادیر X بوده و ستون species مقدار Y می باشد(ما در کد مقدار Y را تغییر میدهیم به طوری که -1 و 1 شود). به ازای هر سطر مقدار Error را پیدا میکنیم و وزنها را آپدیت می کنیم. این کار را چندین بار به ازای تمام مقادیر X و Y انجام میدهیم.
پرسپترون در پایتون
برای پیاده سازی پرسپترون در پایتون کد زیر را استفاده میکنیم:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
class Perceptron(object):
def __init__(self, eta=0.01, n_iter=50, random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
def fit(self, X, y):
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
# print(xi)
self.w_[1:] += update * xi
self.w_[0] = self.w_[0] + update
errors += int(update != 0.0)
self.errors_.append(errors)
return self
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
def predict(self, X):
return np.where(self.net_input(X) >= 0.0, 1, -1)
حال دیتاست خود را آماده میکنیم:
df = pd.read_csv('iris.data', header=None, encoding='utf-8')
y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
X = df.iloc[0:100, [0, 2]].values
در پایان پرسپترون را train می کنیم:
ppn = Perceptron(eta=0.1, n_iter=10)
ppn.fit(X, y)
متغیر eta همان Learning Rate است. n_iter تعداد باری است که کل دیتاها را Train می کنیم. برای نمایش خطا پرسپترون بعد از هر دور، کد زیر را می زنیم:
plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker='o')
plt.xlabel('iteration')
plt.ylabel('Number of updates')
plt.show()
خروجی برنامه به صورت زیر می باشد:
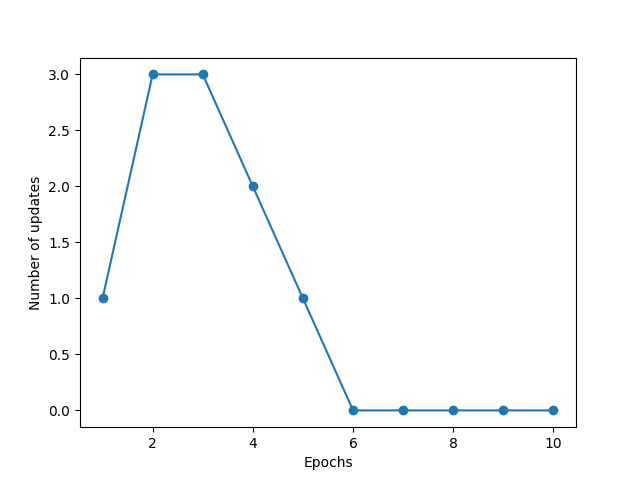
بعد از 6 دور Train کردن خطا نزدیک به صفر شده که نتیجه مناسبی است. شما نیز میتوانید این کد را در برنامههای خود استفاده کنید.