

در این جلسه تیم کدگیت را با آموزش ماشین بردار پشتیبان در پایتون (SVM) همراهی کنید. SVM یکی از الگوریتمهای طبقه بندی بوده که بدلیل سادگی میتوان در ابعاد بالا نیز از آن استفاده کرد. این جلسه به توضیح و پیاده سازی این الگوریتم خواهیم پرداخت. پیشنهاد میکنیم پیش از مطالعه این جلسه، پیشنیازهای زیر را بررسی کنید:
الگوریتم ماشین بردار پشتیبان
یکی از الگوریتم ها و روشهای بسیار رایج در حوزه دسته بندی داده ها، الگوریتم SVM یا ماشین بردار پشتیبان است. SVM برای مسائل رگرسیون نیز کاربرد دارد. اما بیشتر در مسائل طبقه بندی از آن استفاده میکنند. در الگوریتم SVM ، هر داده را به عنوان یک نقطه در فضای n-بعدی ترسیم می کنیم (n تعداد ویژگی های شماست) که ارزش هر ویژگی، مقدار نقطه، در مختصات آن است. سپس، طبقه بندی را با یافتن سطح (صفحهای) که دو کلاس را به خوبی از هم متمایز می کند، انجام می دهیم.
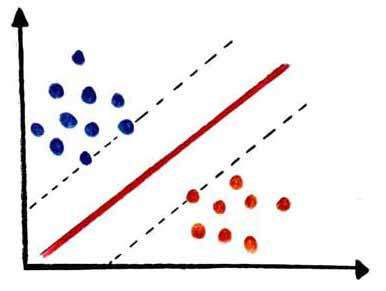
ماشین بردار پشتیبان در پایتون
برای پیاده سازی SVM در پایتون ما از کتابخانه sklearn استفاده خواهیم کرد. دیتایی که الگوریتم SVM را بر روی آن پیاده سازی خواهیم کرد، طبقه بندی قیمت موبایل (دانلود دیتاست) میباشد. دیتاست ما شامل دو هزار (2000) سطر و بیست (20) ستون میباشد. ستونهای دیتاست ما به صورت زیر میباشد:
- battery_power: کل انرژی باتری به mAh
- blue: دارای بلوتوث میباشد یا خیر.
- clock_speed: سرعتی که ریزپردازنده دستورالعمل ها را اجرا می کند.
- dual_sim: تک سیم کارت و دو سیم کارت بودن موبایل
- FC: مخفف Front Camera یا دوربین جلو بوده و مقدار این ستون به مگاپیکسل میباشد.
- four_g: قابلیت g4 را دارد یا خیر.
- int_memory: مخفف internal memory بوده و مقدار آن به گیگابایت میباشد.
- m_dep: عرض تلفن همراه به سانتی متر (Mobile depth)
- mobile_wt: وزن موبایل.
- n_cores: تعداد هستههای پردازنده
- Pc: مخفف Primary camera یا دوربین اصلی بوده و مقدار آن به مگاپیکسل است.
- px_height: وضوح تصویر (ارتفاع)
- px_width: وضوح تصویر (عرض)
- ram: این ستون برای همه ما شفاف هستJ
- sc_h: ارتفاع صفحه نمایش تلفن همراه در سانتی متر
- sc_w: عرض صفحه تلفن همراه در سانتی متر
- talk_time: طولانی ترین زمانی که یک بار شارژ باتری دوام میآورد (هنگام استفاده).
- three_g: پشتیبانی از 3g
- touch_screen: صفحه لمسی دارد یا خیر
- wifi: پشتیبانی از wifi
- price_range: رنج قیمت تلفن همراه. در این دیتاست تلفنهای همراه در چهار (4) رنج قیمت با توجه به قابلیتهای موبایل قرار میگیرند.
- رنج قیمت صفر به معنی قیمت پایین است.
- رنج قیمت 1 به معنی قیمت متوسط است.
- رنج قیمت 2 به معنی قیمت بالا است.
- o رنج قیمت 3 به معنی خیلی بالا میباشد.
ابتدا دیتاست خود را وارد کد کرده و بر روی پیش پردازش میکنیم:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme()
mobile = pd.read_csv('MobilePrice.csv')
بخشی از دیتا به صورت زیر میباشد:

توابع describe و info را برای بدست آوردن اطلاعات کلی از دیتا صدا میزنیم:
mobile.info()
mobile.describe()
خروجی توابع بالا به صورت زیر است:
class 'pandas.core.frame.DataFrame'>
RangeIndex: 2000 entries, 0 to 1999
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 battery_power 2000 non-null int64
1 blue 2000 non-null int64
2 clock_speed 2000 non-null float64
3 dual_sim 2000 non-null int64
4 fc 2000 non-null int64
5 four_g 2000 non-null int64
6 int_memory 2000 non-null int64
7 m_dep 2000 non-null float64
8 mobile_wt 2000 non-null int64
9 n_cores 2000 non-null int64
10 pc 2000 non-null int64
11 px_height 2000 non-null int64
12 px_width 2000 non-null int64
13 ram 2000 non-null int64
14 sc_h 2000 non-null int64
15 sc_w 2000 non-null int64
16 talk_time 2000 non-null int64
17 three_g 2000 non-null int64
18 touch_screen 2000 non-null int64
19 wifi 2000 non-null int64
20 price_range 2000 non-null int64
dtypes: float64(2), int64(19)
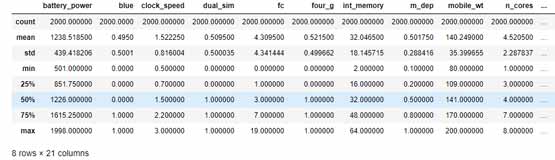
از روی میانگین بدست امده از ستونها در تصویر بالا، میتوان به این نتیجه رسید دیتا نیازمند نرمال سازی است. دیتا خود را با کد زیر نرمال میکنیم:
y = mobile["price_range"].values
temp=mobile.drop(["price_range"],axis=1)
x = (temp-np.min(temp))/(np.max(temp)-np.min(temp))
پیاده سازی الگوریتم SVM
در قسمت قبل دیتا را وارد برنامه و آن را نرمال کردیم. حال نیاز داریم دیتا را به دو قسمت test و train تقسیم کرده و سپس الگوریتم SVM را روی آن پیاده سازی کنیم.
ابتدا دیتا را به دو قسمت Test و Train تقسیم میکنیم:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x,y,test_size=0.20,random_state=1)
حال نوبت به پیاده سازی الگوریتم SVM رسیده است. به کمک کتابخانه sklearn این الگوریتم را پیاده سازی میکنیم:
from sklearn.svm import SVC
svm=SVC(random_state=1)
svm.fit(X_train,y_train)
حال برای ارزیابی الگوریتم SVM کد زیر را میزنیم:
print("test accuracy:",svm.score(X_test,y_test))
خروجی کد بالا برابر است با:
test accuracy: 0.8375
خروجی ما خوب نیست. با چند روش میتوانیم نتیجه الگوریتم را بهتر کنیم:
- کاهش ابعاد دیتا
- نرمال سازی
- پیدا کردن بهترین پارامترها برای الگوریتم SVM (پارامترهایی مانند گاما و …)
بهتر کردن نتیجه این دیتاست رو به شما میسپاریم.
اگر سوالی در خصوص ماشین بردار پشتیبان در پایتون دارید در قسمت کامنت سوال خود را مطرح کنید تا پاسخگوی شما باشیم.











سلام تشکر
خیلی خوب بود
فقط یه سوال اینکه این عدد نهایی چی هست دقیقا
یعنی چیو داره تووی بردار پشتیبان نشون میده؟
سلام. در این مثال ما می خواهیم رنج قیمت یک تلفن همراه را بر اساس ویژگی های گفته شده پیش بینی کنیم. برای این کار ما رنج قیمت موبایل (تلفن همراه) را به 4 دسته صفر(قیمت پایین)، یک (قیمت متوسط)، دو (قیمت بالا و سه (قیمت خیلی بالا) تقسیم کردیم و سپس پیش بینی می کنیم یک موبایل چه قیمتی دارد. در خروجی دسته قیمت یک موبایل (در این مثال اعداد 0 یا 1 یا دو یا سه به ما می دهد.)
ممنون بله
متوجهم
ولی سوالم اینه که خروجی مفهومش چیه؟
test accuracy: 0.8375
این عدد یعنی چی>
وقتی بر روی دیتاها فرآیند train را انجام دادیم. به مرحله تست خواهیم رسید. عدد 0.8375 نتیجه تست ما بر روی دیتا تست است. این بدین معنی است که الگوریتم SVM با روش ما حدود 83% درست جواب می دهد.
from sklearn.svm import SVC
svm=SVC(random_state=1)
svm.fit(X_train,y_train)
بعد از run کد بالا یه ستاره می مونه تو نوت بوک و هیچی اجرا نمیشه
در کل خروجی نمی بینم. ممنون میشم راهنمایی کنید
سلام. کدی که در کامنت به آن اشاره کردید خروجی ندارد. پس از اجرا می توانید دقت ماشین بردار پشتیبان با توجه به دیتای ورودی به چاپ برسانید. کد آن در بالا آمده است.
سلام مجدد امکانش هست کد محاسبه FPR و AUC رو هم بگذارید
با تشکر
سلام روزتون بخیر من میخوام از الگوریتم svm برای فارنزیک موبایل استفاده کنم ولی نمیدونم چجور دیتاستش رو پیدا کنم یا تهیه کنم و کارم واقعا لنگ این موضوع میشه راهنمایی کنین؟
سلام وقت بخیر. سایت های معتبر زیادی در خصوص انتشار دیتا فعالیت دارند. از جمله این وب سایت ها می توان به Kaggle یا google data search یا UCI یا … اشاره کرد. البته github نیز برخی دیتاست ها را در خود جای داده که می توان از آن استفاده کرد.